Artificial intelligence in healthcare: Fundamentals
During the process of designing and selecting the best model approach, there are few methods or approaches, namely: train and test, cross -validation and train, validation and test. In the first method, a dataset is randomly split into two sets, a larger training dataset used to train a decision model, and a smaller test dataset used to test the newly trained model. In the Cross-validation approach, the dataset is split into k many randomly selected subsets (using a pre-defined size k). In each stage, one subset plays the role of validation set, whereas the other remaining parts (K-1) are the training set. For each stage, it involves removing part of the data, then holding it out, fitting the model to the remaining part, and then applying the fitted model to the data that we've held out. Performance results for each iteration are averaged to produce less variable performance results. In the last approach, the dataset is randomly split into train, validation, and test sets. The training dataset is used to train the decision model. The validation dataset is then used to iteratively test the decision model, and update its parameters for optimal performance. Once model parameters have been configured for optimal results, the model is then evaluated using the test dataset (see figure 9).
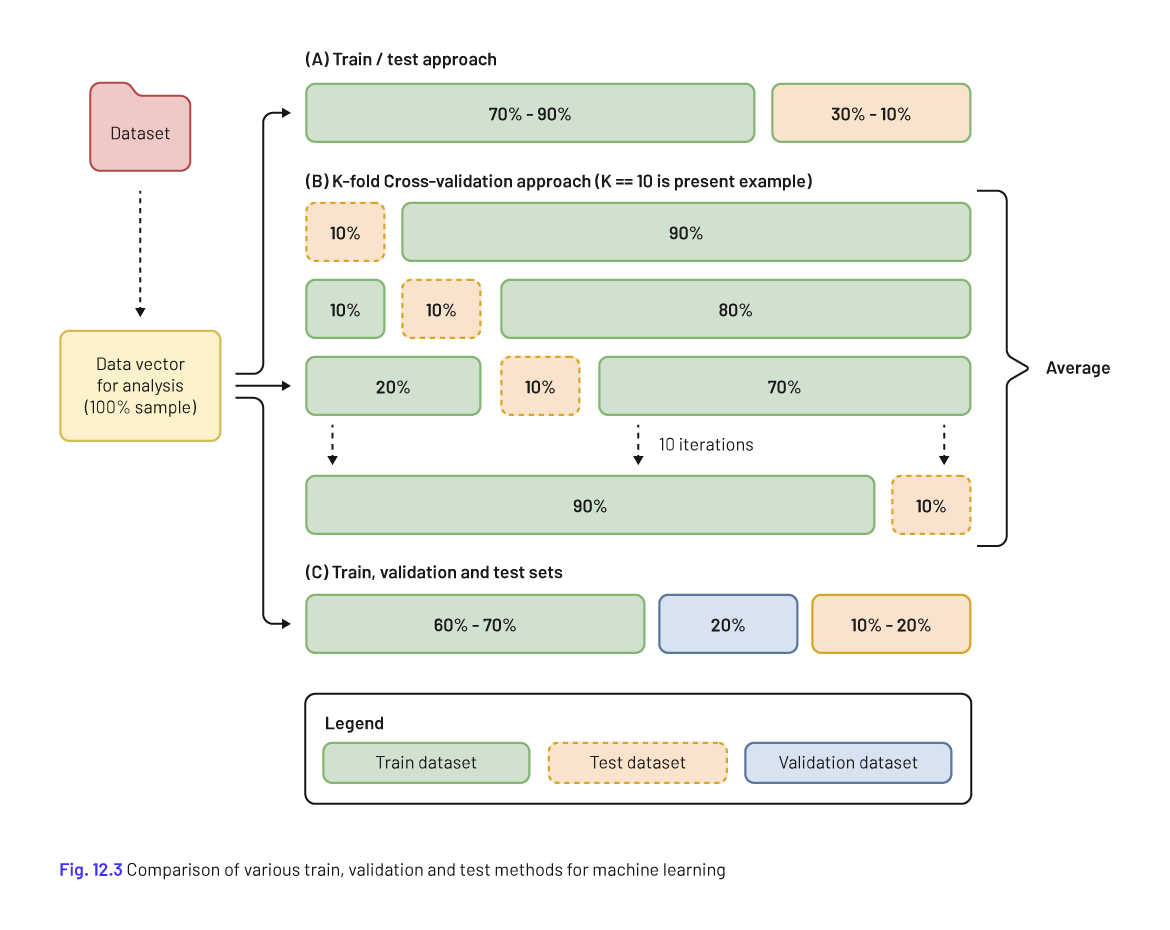
Figure 9 - Methods to design and develop an algorithm of machine learning. Image available at (Magnuson J.A., 2020)
Likewise, it is essential to evaluate the performance characteristics of a decision model. For this some used performance metrics are: sensitivity (i.e. the proportion of actual positives that are correctly identified); specificity (i.e. the proportion of actual negatives that are correctly identified); precision (i.e. the proportion of positive identifications that are correct); F1-score (i.e. accuracy measure representing an average used for numbers that represent rate or ratio between precision and sensitivity; and Area under the Receiver Operator Characteristic curve (AUC ROC) which demonstrates through a graphical plot the diagnostic performance of a classification model across various threshold configurations (this score can range between 0-1).
To wrap up, a model learns relationships between the inputs (features) and outputs (labels) from a training dataset. Models can take many shapes, such as logistic regression – described in the previous section.
However, ML algorithms are not free of constraints. While building these models, researchers should be aware and concern on some challenges. Overfitting, broadly speaking and in contrast to underfitting, means the training fits exactly against its training data, resulting in inability to generalize to unseen datasets. This happens when noise (irrelevant or incorrect data elements) is included in the dataset. In the other hand, underfitting means the model has not captured the underlying logic of the data; thus it is unable to properly perform across both the current and new datasets. Finally, class imbalance occurs when classes are not present in proportion across the dataset, i.e., the occurrence of one of the classes is very high compared to the other classes present (there is a bias or skewness towards the majority class present in the target). Two sampling methods are usually used to address this problem: oversampling (supplementing with observations of minority instances) and undersampling (removing instances of the majority class).