3. Big Data and secondary data
Secondary data is defined as data used for different purposes of the ones they were originally collect for. Secondary data sources have been gaining attention as they provide an unparalleled retrospective opportunity to capture information across the entire system of health (see example 4).
There are several main sources of secondary data, including administrative databases, electronic health records, scientific literature, or scientific reports, surveys and internet-based data.
Some of the most visible advantages of secondary data are carrying out studies with less cost (most obvious one), in less time and with a larger sample size, which are also useful to raise new research hypotheses. Other advantages include the possibility of assessing long periods of time and large geographical areas (e.g. entire regions or nations). The analysis of large volumes of secondary data can overcome some limitations of “traditional” observational studies based on primary data, however concerns remain about these databases related to their possible heterogeneity and lack of control during the collection process - with possible omission and lack of quality of the data. In fact, inherent to the nature of the secondary analysis, since any available data has been previously collected for other purpose its obvious this can lead to missing information on some important third variable or some specific segment of the population. Moreover, researchers who are analyzing the data are not usually the same individuals as those involved in the data collection process, so they may not be aware of some specifics that can lead to misinterpretation of the findings. Succinct documentation of important information about the validity of the data can partly mitigate this problem.
Data, data sources and types of data
We consider a clinical datum to be any single observation of a patient—e.g., a temperature reading, a red blood cell count, a past history of rubella, or a blood pressure reading. If a clinical datum is a single observation about a patient, clinical data are multiple observations (see example 3).
There is a broad range of data types/formats in the practice of medicine and the allied health sciences. They range from narrative, textual data to numerical measurements, genetic information, recorded signals, drawings, and even photographs or other images.
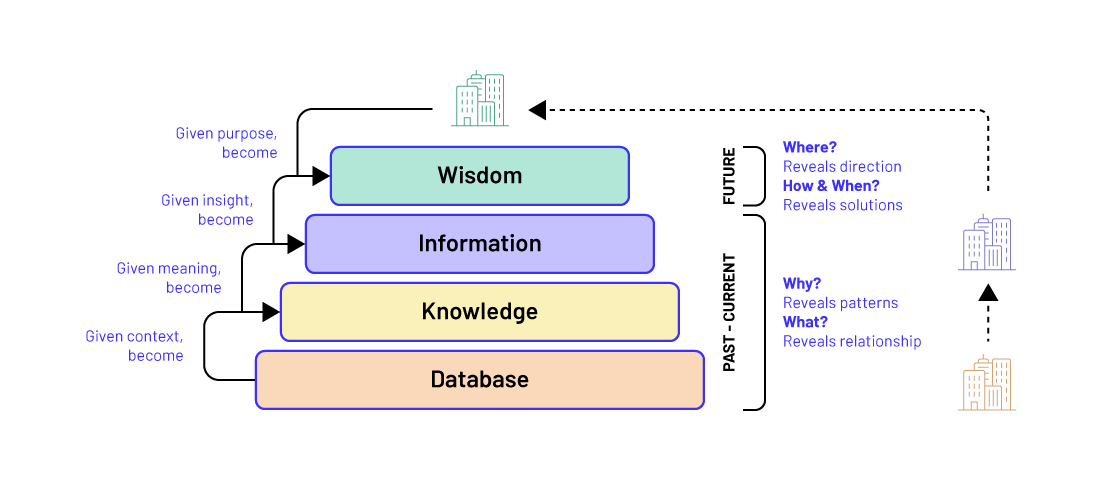
A database is a collection of individual observations (i.e., data) without any summarizing analysis. An Electronic medical record (EHR) system is thus primarily viewed as a database— the place where patient data are stored. When properly collected and analyzed with other data, these elements in the EHR provide information about the patient.
In fact, EHR has been described as a general term describing computer-based patient record systems. However, it is sometimes extended to include other functions like order entry for medications and tests, amongst other common functions which can start to actively support clinical care by providing a wide variety of information services. There are various types of EHR, namely:
· Electronic Medical Record (EMR) - includes all information (clinical and administrative) of one patient and focuses on relevant information for specific medical problem episodes;
- Electronic Patient Record (EPR) - is an organised collection of all records about an individual patient stored in the computer systems and databases of all the providers who have provided care to that patient within an enterprise;
- Virtual Patient Records (VPRs) - is a record that is not stored on any individual computer, but assembled dynamically, in real time, from various systems when needed;
- Electronic Health Record (EHR) - is a longitudinal record of patients' health. It combines information about patients’ contacts with primary care and subsets of information associated with the outcomes of periodic care whether held in EMRs, EPRs or other information systems.
- Personal Health Record (PHR) - is a record that allows patient empowerment through personal management and sharing of personal health information.
Other examples of health data sources are provided in example 5.
Data from different sources are used for multiple purposes at different levels of the health care system. In fact, we can stratify data in individual level, health facility level data, population level data and public health surveillance. For example, the patient's profile, health care needs and treatment serves as the basis for clinical decision-making for individual clinical care while aggregated facility-level records from administrative sources enable health care managers to determine resource needs.
A data lake is a system or repository of data stored in its natural form (usually files). A data lake is typically a single repository of all business data, including raw copies of data from the source system and transformed data used for tasks such as reporting, visualization, analytics, and machine learning. Data Lakes increase agility and provide more opportunities for data exploration and proof of concept activities, as well as self-service business intelligence, within predefined privacy and security settings.
Remember:
DATA refers to raw numbers or other measures (objective facts about events) while INFORMATION refers to what emerges when data are processed, analyzed, interpreted, and presented. In other words, Information is Data transformed (contextualized, categorized, corrected, calculated, condensed) into a message. The key to any successful big data initiative is the ability to get information from the vast deluge of data, separating the noise from the signal.